Variational Bayesian Inference for Audio-Visual Tracking of Multiple Speakers
Résumé
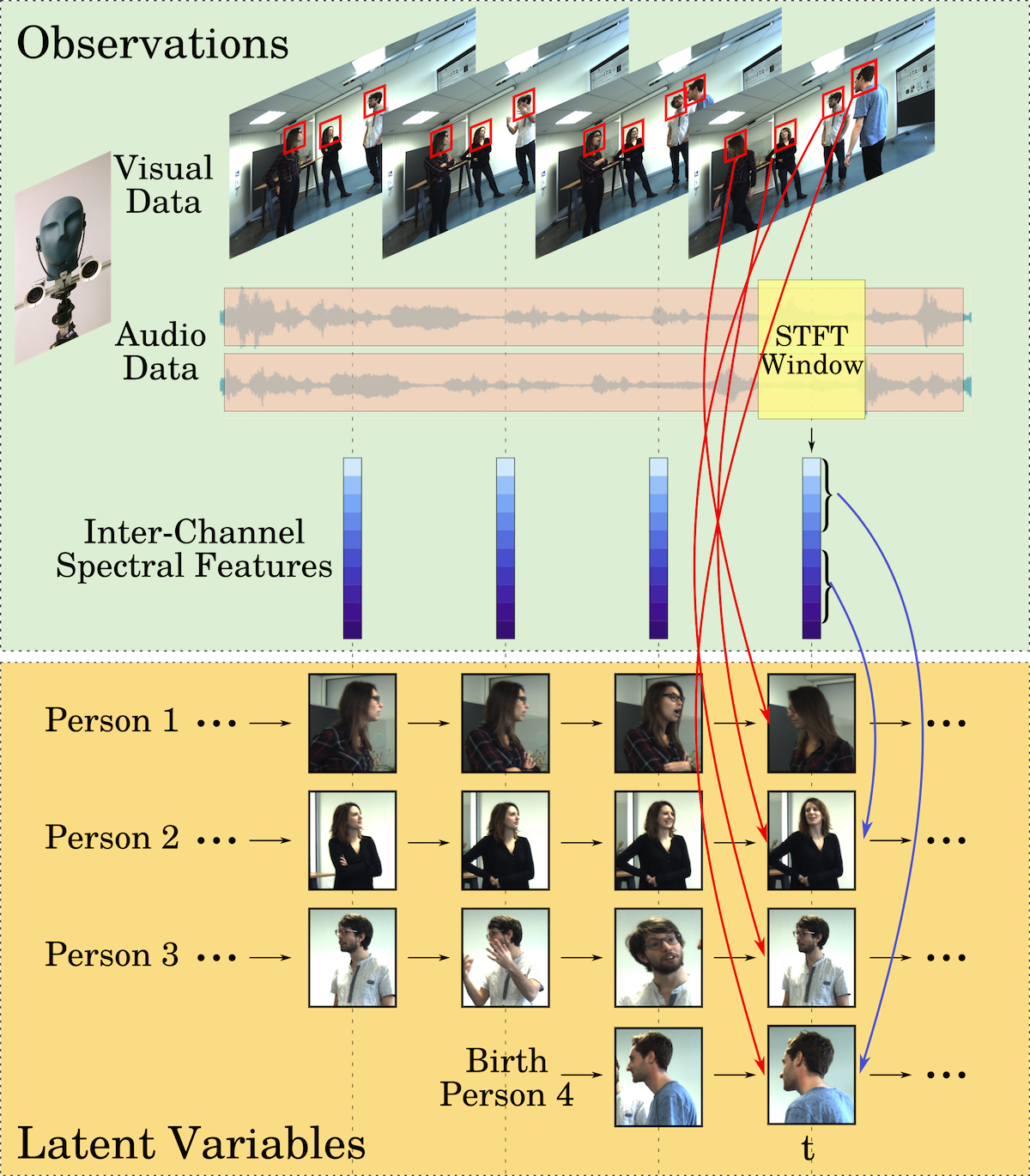
In this paper we address the problem of tracking multiple speakers via the fusion of visual and auditory information. We propose to exploit the complementary nature and roles of these two modalities in order to accurately estimate smooth trajectories of the tracked persons, to deal with the partial or total absence of one of the modalities over short periods of time, and to estimate the acoustic status - either speaking or silent - of each tracked person over time. We propose to cast the problem at hand into a generative audio-visual fusion (or association) model formulated as a latent-variable temporal graphical model. This may well be viewed as the problem of maximizing the posterior joint distribution of a set of continuous and discrete latent variables given the past and current observations, which is intractable. We propose a variational inference model which amounts to approximate the joint distribution with a factorized distribution. The solution takes the form of a closed-form expectation maximization procedure. We describe in detail the inference algorithm, we evaluate its performance and we compare it with several baseline methods. These experiments show that the proposed audio-visual tracker performs well in informal meetings involving a time-varying number of people.
Fichier principal
 BAN_PAMI_V3 (1).pdf (11.06 Mo)
Télécharger le fichier
BAN_PAMI_V3 (1).pdf (11.06 Mo)
Télécharger le fichier
 overview (1).png (1.21 Mo)
Télécharger le fichier
overview (1).png (1.21 Mo)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image
Loading...