Audio-Visual Clustering for Multiple Speaker Localization
Résumé
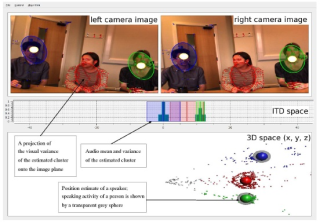
We address the issue of identifying and localizing individuals in a scene that contains several people engaged in conversation. We use a human-like configuration of sensors (binaural and binocular) to gather both auditory and visual observations.We show that the identification and localization problem can be recast as the task of clustering the audio-visual observations into coherent groups. We propose a probabilistic generative model that captures the relations between audio and visual observations. This model maps the data to a representation of the common 3D scene-space, via a pair of Gaussian mixture models. Inference is performed by a version of the Expectation Maximization algorithm, which provides cooperative estimates of both the activity and the 3D position of each speaker.
Fichier principal
 mlmi2008.pdf (363.23 Ko)
Télécharger le fichier
mlmi2008.pdf (363.23 Ko)
Télécharger le fichier
 mlmi08.jpg (84.46 Ko)
Télécharger le fichier
mlmi08.jpg (84.46 Ko)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image