A Spatio-Temporal Descriptor Based on 3D-Gradients
Résumé
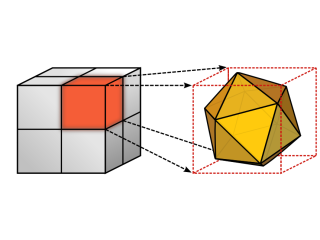
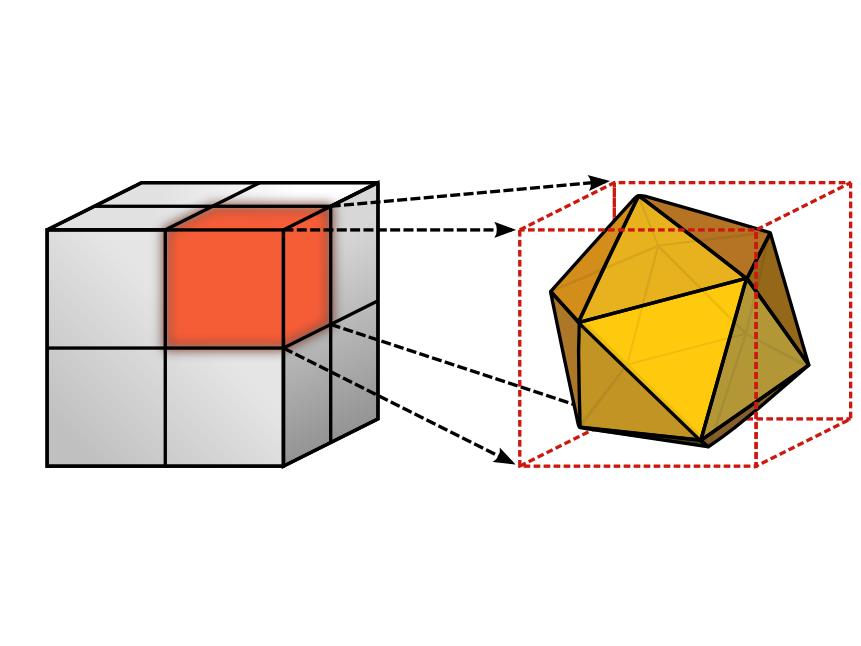
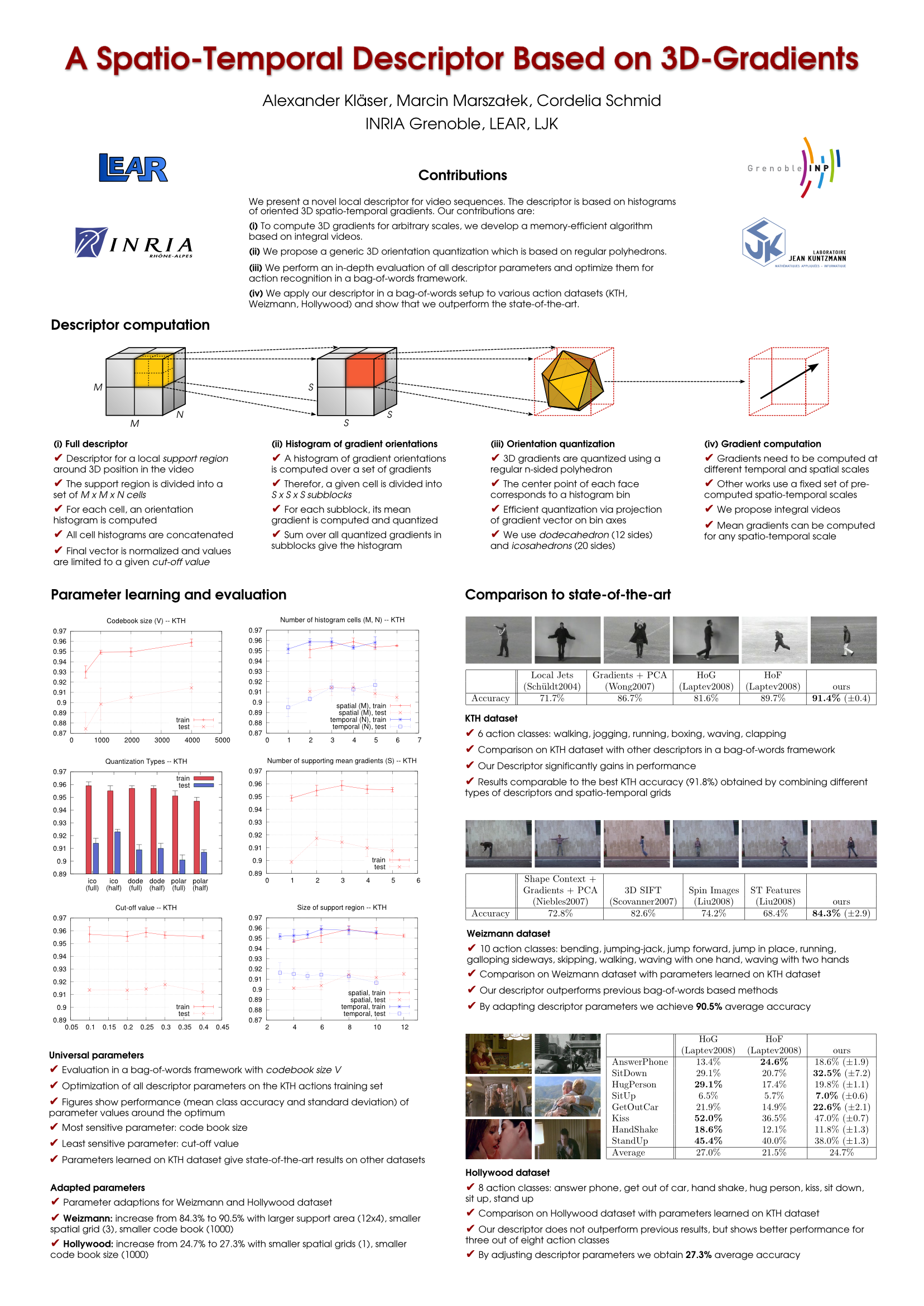
In this work, we present a novel local descriptor for video sequences. The proposed descriptor is based on histograms of oriented 3D spatio-temporal gradients. Our contribution is four-fold. (i) To compute 3D gradients for arbitrary scales, we develop a memory-efficient algorithm based on integral videos. (ii) We propose a generic 3D orientation quantization which is based on regular polyhedrons. (iii) We perform an in-depth evaluation of all descriptor parameters and optimize them for action recognition. (iv) We apply our descriptor to various action datasets (KTH, Weizmann, Hollywood) and show that we outperform the state-of-the-art.
Fichier principal
 KlaserMarszalekSchmid-BMVC08-3DGradientDescriptor.pdf (317.46 Ko)
Télécharger le fichier
KlaserMarszalekSchmid-BMVC08-3DGradientDescriptor.pdf (317.46 Ko)
Télécharger le fichier
 3ddesc.png (63.16 Ko)
Télécharger le fichier
poster.png (1.28 Mo)
Télécharger le fichier
3ddesc.png (63.16 Ko)
Télécharger le fichier
poster.png (1.28 Mo)
Télécharger le fichier
{kind=link}
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image
Format : Autre
Loading...