Weakly supervised learning of interactions between humans and objects
Résumé
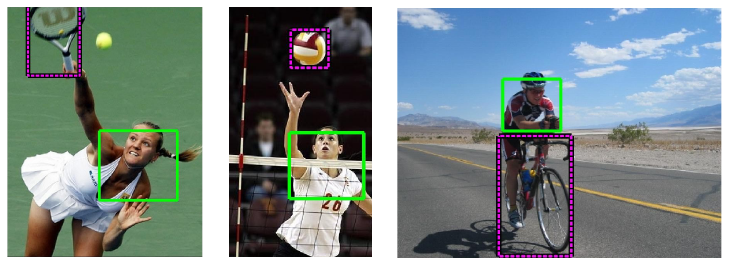
We introduce a weakly supervised approach for learning human actions modeled as interactions between humans and objects. Our approach is human-centric: we first localize a human in the image and then determine the object relevant for the action and its spatial relation with the human. The model is learned automatically from a set of still images annotated (only) with the action label. Our approach relies on a human detector to initialize the model learning. For robustness to various degrees of visibility, we build a detector that learns to combine a set of existing part detectors. Starting from humans detected in a set of images depicting the action, our approach determines the action object and its spatial relation to the human. Its final output is a probabilistic model of the human-object interaction, i.e. the spatial relation between the human and the object.
Fichier principal
 RT-0391.pdf (3.43 Mo)
Télécharger le fichier
RT-0391.pdf (3.43 Mo)
Télécharger le fichier
 Screenshot.png (263.69 Ko)
Télécharger le fichier
Screenshot.png (263.69 Ko)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image
Loading...