Action and Event Recognition with Fisher Vectors on a Compact Feature Set
Résumé
Action recognition in uncontrolled video is an important and challenging computer vision problem. Recent progress in this area is due to new local features and models that capture spatio-temporal structure between local features, or human-object interactions. Instead of working towards more complex models, we focus on the low-level features and their encoding. We evaluate the use of Fisher vectors as an alternative to bag-of-word histograms to aggregate a small set of state-of-the-art low-level descriptors, in combination with linear classifiers. We present a large and varied set of evaluations, considering (i) classification of short actions in five datasets, (ii) localization of such actions in feature-length movies, and (iii) large-scale recognition of complex events. We find that for basic action recognition and localization MBH features alone are enough for state-of-the-art performance. For complex events we find that SIFT and MFCC features provide complementary cues. On all three problems we obtain state-of-the-art results, while using fewer features and less complex models.
Fichier principal
 paper.pdf (208.04 Ko)
Télécharger le fichier
paper.pdf (208.04 Ko)
Télécharger le fichier
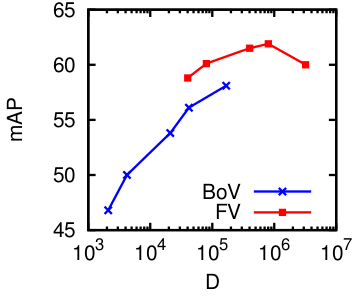
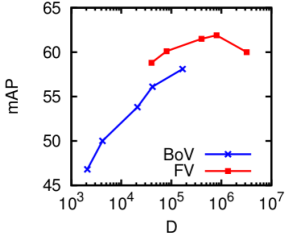 Selection_001.png (14.54 Ko)
Télécharger le fichier
Selection_001.png (14.54 Ko)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image
Loading...