Overfitting using the MDL principle
Résumé
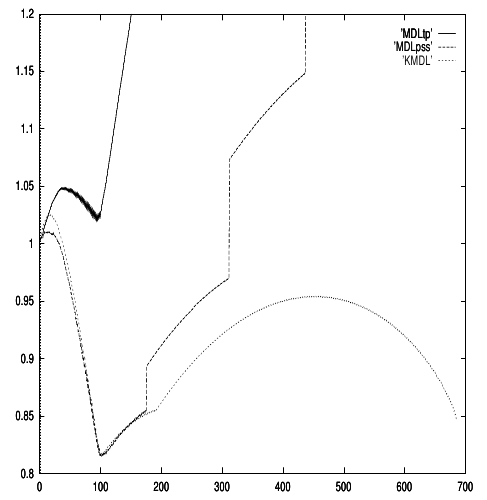
This thesis investigates the experimental results obtained in the paper "An experimental and theoretical comparison of model selection methods" by Kearn, Mansour, Ng, and Ron, published in volume 27 of Machine Learning 1997 (referred to as [KMNR97]). These 'model selection methods' are used to find a 'good' model for some observed data. The data consists of pairs (x,y). Often the 'x-data' is regarded as given and the model is a function that maps each x-value to a y-value. We concentrate on the 'overfitting' behavior of the Two-Part Minimum Description Length (henceforth MDL) principle. Furthermore we also consider Guaranteed Risk Minimization (GRM), Predictive MDL and Cross Validation. We verify and extend the experiments as published in [KMNR97]. The conclusions of the analysis of these experiments lead to a second series of experiments. A second series of experiments was conducted to test under which conditions the conjecture holds that removing bad models from the model class can actually decrease performance. We conclude the following: 1. Using small model classes may lead to overfitting, if the sample is corrupted by noise. Using the, given, x-data to code models is one way to work with small model classes for small sample sizes. This phenomenon does not only affect Two-Part MDL, as suggested by the experimental results in [KMNR97], but also GRM. It is difficult to design a general learning algorithm that is guaranteed not to overfit the data. However, it became clear that, when we use Two-Part MDL or GRM, it is wise to keep the model class sample-independent in order to avoid overfitting. 2. Predictive MDL does not overfit on the interval function selection problem. However, it is non-parametric, its performance is not dependent on the size of the model class, it does not overfit much and it overfits only for small sample sizes. 3. The Two-Part MDL principle performs well on selecting a model class and thus the number of parameters, but does no necessarily provide good estimates for the parameter values, so for an actual model. It is better to use Two-Part MDL just to edtimate the number of parameters. Within the selected model class Maximum Likelihood can be used to find the best model with number of parameters suggested by Two-Part MDL.
Domaines
Apprentissage [cs.LG]
Fichier principal
 verbeek98msc.pdf (1.28 Mo)
Télécharger le fichier
verbeek98msc.pdf (1.28 Mo)
Télécharger le fichier
 Ver98.png (22.06 Ko)
Télécharger le fichier
Ver98.png (22.06 Ko)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image