Trans Media Relevance Feedback for Image Autoannotation
Résumé
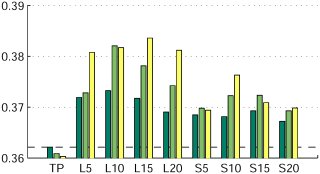
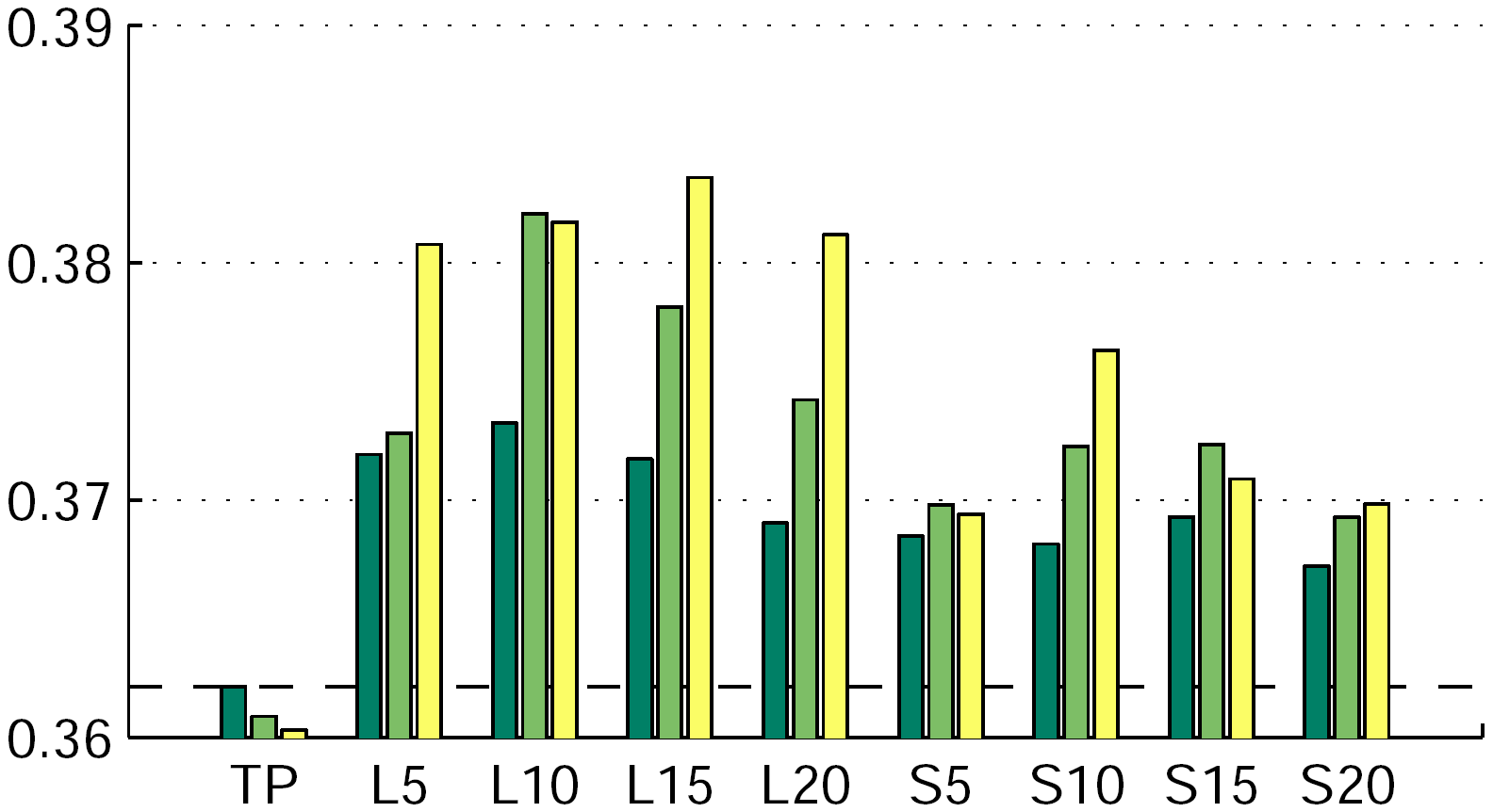
Automatic image annotation is an important tool for keyword-based image retrieval, providing a textual index for non-annotated images. Many image auto annotation methods are based on visual similarity between images to be annotated and images in a training corpus. The annotations of the most similar training images are transferred to the image to be annotated. In this paper we consider using also similarities among the training images, both visual and textual, to derive pseudo relevance models, as well as crossmedia relevance models. We extend a recent state-of-the-art image annotation model to incorporate this information. On two widely used datasets (COREL and IAPR) we show experimentally that the pseudo-relevance models improve the annotation accuracy.
Fichier principal
 MVC10.pdf (118.69 Ko)
Télécharger le fichier
MVC10.pdf (118.69 Ko)
Télécharger le fichier
 GVS11a.png (22.91 Ko)
Télécharger le fichier
GVS11a.png (22.91 Ko)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image
Loading...