Human Action Description
Résumé
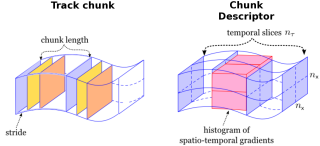
This master thesis describes a supervised approach to recognize human actions in video sequences. With human action we can understand human action classification and human action localization. In human action classification, the goal is to issue an action class label to sequences with pre-defined temporal extent. In human action localization, the objective is to localize human actions in space (the 2D image region) and in time (temporal extent). In this thesis, we are interested in action classification and localization tasks. The type of video data used are controlled and uncontrolled (realistic) video sequences. In realistic type of video data, human action recognition is especially difficult due to variations in motion, view-point, illumination, camera ego-motion, and partial occlusion of humans. In addition to that, action classes are subject to large intra-class variabilities due to the anthropometric differences across humans. In the case of action localization, the search is computationally expensive due to the large volume of video data. Recently, global representations have shown impressive results for action localization in realistic videos. Nevertheless, these representations have not been applied to repetitive actions, such as running, walking etc. In fact, they even seem not appropriate for this type of actions. Therefore, we propose and evaluate in this work a novel approach that addresses this problem by representing actions as loose collection of movement patterns. To recognize actions in video, we first detect and track human positions throughout time. We then represent human tracks by a series of overlapping chunks segments. These track chunks are processed independently. For our action representation, we extract appearance and motion information with histograms of spatio-temporal gradient orientations. Since chunks with a high affinity to an action of interest will be classified with a larger score, the beginning and end of an action (i.e., action localization) can be determined with clustering approaches. For our method, we employ a variable band-with meanshift. Our results on publicly available datasets demonstrate and advantage of our method, especially for repetitive type of actions. On realistic data and for non-repetitive actions, we are able to compete with the state-of-the-art results for some action classes and loose for other classes.
Fichier principal
 thesis.pdf (4.24 Mo)
Télécharger le fichier
thesis.pdf (4.24 Mo)
Télécharger le fichier
 hogChunk.png (191.07 Ko)
Télécharger le fichier
defense.pdf (5.6 Mo)
Télécharger le fichier
hogChunk.png (191.07 Ko)
Télécharger le fichier
defense.pdf (5.6 Mo)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image
Format : Autre
Loading...