Action Tubelet Detector for Spatio-Temporal Action Localization
Résumé
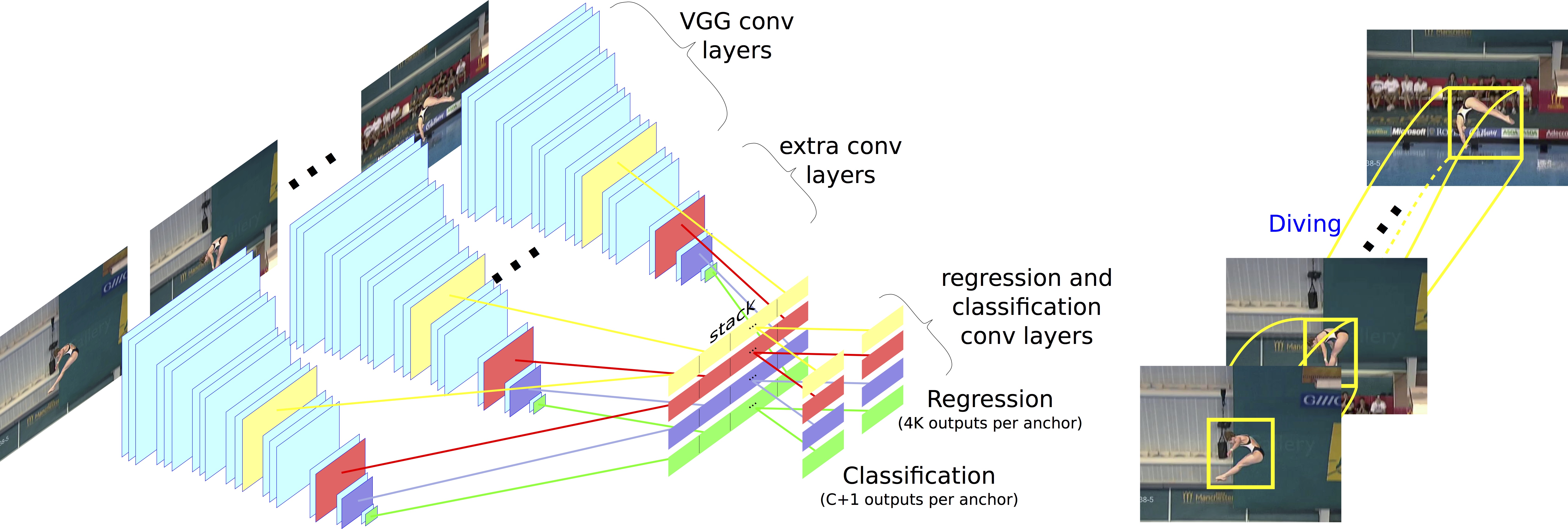
Current state-of-the-art approaches for spatio-temporal action detection rely on detections at the frame level that are then linked or tracked across time. In this paper, we leverage the temporal continuity of videos instead of operating at the frame level. We propose the ACtion Tubelet detector (ACT-detector) that takes as input a sequence of frames and outputs tubelets, ie., sequences of bounding boxes with associated scores. The same way state-of-the-art object detectors rely on anchor boxes, our ACT-detector is based on anchor cuboids. We build upon the state-of-the-art SSD framework. Convolutional features are extracted for each frame, while scores and regressions are based on the temporal stacking of these features, thus exploiting information from a sequence. Our experimental results show that leveraging sequences of frames significantly improves detection performance over using individual frames. The gain of our tubelet detector can be explained by both more relevant scores and more precise localization. Our ACT-detector outperforms the state of the art methods for frame-mAP and video-mAP on the J-HMDB and UCF-101 datasets, in particular at high overlap thresholds.
Fichier principal
 main.pdf (6.29 Mo)
Télécharger le fichier
main.pdf (6.29 Mo)
Télécharger le fichier
 fig2-SSTD_network.jpg (1.38 Mo)
Télécharger le fichier
fig2-SSTD_network.jpg (1.38 Mo)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image
Origine : Fichiers produits par l'(les) auteur(s)
Origine : Fichiers produits par l'(les) auteur(s)
Loading...